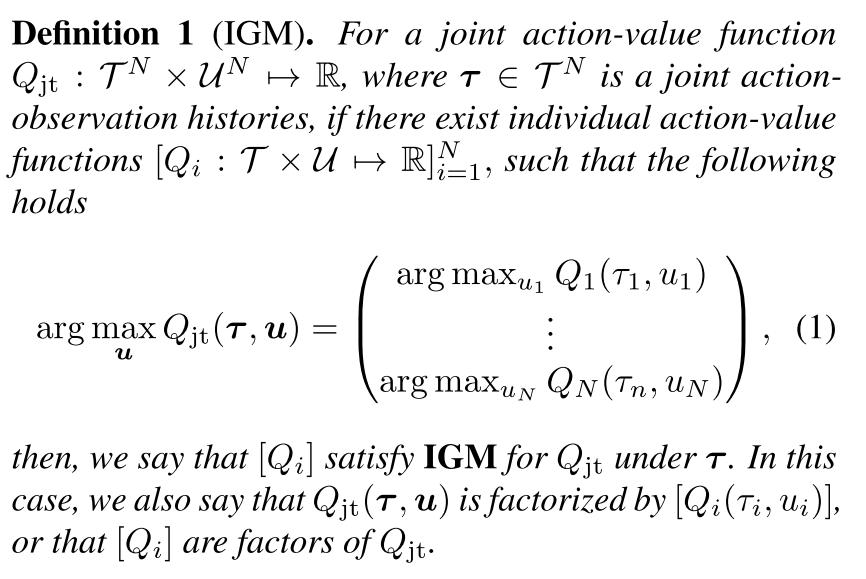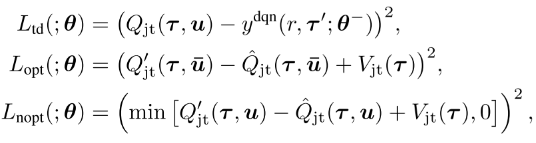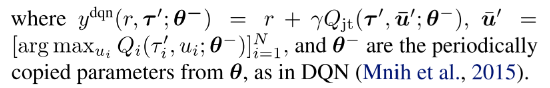1.2 协作MARL: QTRAN
论文及翻译:QTRAN
1 Motivation
我们已经知道了去中心化方法可扩展性好, 但是存在不稳定的问题, 而中心化方法可以解决非稳定性问题, 但是随智能体数量增加, 算法复杂度爆炸式增长. 基于值分解方法的中心化训练去中心化执行算法可以同时结合上述两者的优点, 且复杂性可以控制. 典型的就是VDN、QMIX算法和Qatten、QTRAN算法等.
值分解方法定义为, 当联合Q值取得得最优动作时, 每一个个体的Q值也得到最优动作, 即下述的IGM(Individual-Global-Max)
即, 当[Qi]对Qjt满足IGM时, 可以说[Qi]是Qjt的值分解.
为了使[Qi]和Qjt满足IGM, VDN算法使用加性约束, QMIX算法使用单调性约束. 但这两个算法中显得过度约束, 限制了智能体的种类.
QTRAN算法设计了一个转换函数, 把原始联合Q值函数Qjt变为Qjt′, 使其与Qjt具有相同的最优动作, 并解除加性/单调性约束, 其中使用了一个状态值函数更正部分观察带来的偏差.
2 算法原理
 |
| Figure 1. DEC-POMDP |
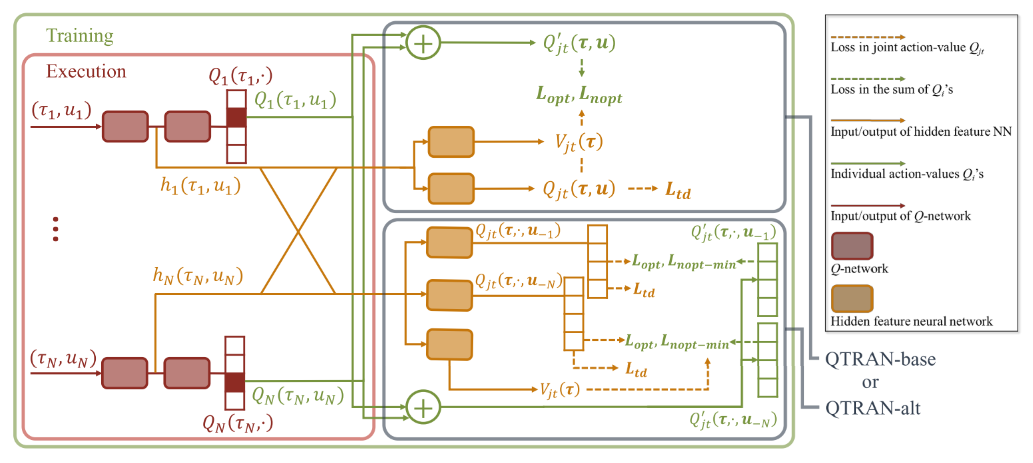
QTRAN算法包括三个部分: 联合动作值网络、个体动作值网络、状态网络, 每个部分都有各自的loss函数进行训练.
同时论文作者设计了两种QTRAN算法: QTRAN-base和QTRAN-alt. 这两种算法的区别在于如何构造非最优动作Q值的转换函数、收敛速度和稳定性.
 |
| Figure 1. QTRAN-base and QTRAN-alt Architecture |
2.1 QTRAN-base
定义μ¯i=argmaxμiQi(τi,μi)表示最优动作, u¯=[μ¯i]i=1N; 令Q=[Qi]∈RN, 即Qi,i=1,...,N的列向量.
定理1 给出[Qi]满足IGM的充分条件.
| 一个可分的联合Q值函数Qjt(t,u), 可以被[Qi(τi,μi)]分解, 当 |
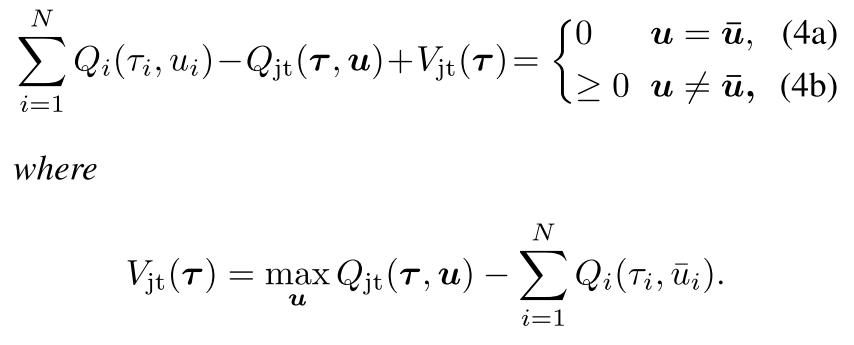 |
把上面的公式展开就能理解他的意思,
- 当U是最优联合动作时, 公式左边等于0(4a), 那么[Qi]是Qjt的分解;
- 当U不是最优联合动作时, 同样的理解, (maxQjt−Qjt)−(∑Qi(;ui¯)−∑Qi(ui))>0.
变换函数
作者的思路就是构造一个变换的加性联合Q值函数,
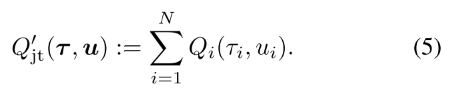
通过加性结构, [Qi]满足Qjt′的IGM, 那么它就是Qjt′的分解个体Q值函数. 因为argmaxuQjt(t,u)=argmaxuQjt′(t,u), 找到[Qi]满足(4)就是Qjt′(t,u)的分解.
函数Vjt(t)用来修正中心化联合Q函数Qjt和[Qi]的和的偏差. 偏差是智能体部分观察带来的. 如果加入了全局观察, Vjt可以设为0.
网络结构和作用
个体Q网络, 每个智能体i的Q值加和得Qjt′;
联合Q网络: 逼近Qjt, 输入为选择的动作, 输出为该动作得Q值.
- 首先使用所有个体Q网络采样的动作向量来更新联合Q网络. 因为联合动作空间UN, 找到最优联合动作复杂度很高, 而每个个体的最优动作取argmax就行, 是线性的.
- 第二, 联合Q网络共享个体网络低层的参数, 联合Q网络把个体网络隐层特征加和整合∑ihQ,i(τi,ui), 其来自于hi(τi,ui)=[hQ,i(τi,ui),hV,i(τi)].(使用此参数共享样本效率高, 可进行可扩展的训练, 但会牺牲表达能力.)
状态值网络: 计算标量状态价值, 类似与dueling网络的V(s).
- 用来在计算argmax时匹配Qjt和Qjt′+Vjt. 没有V, 部分观察可能限制Qjt′的表达复杂性;
- 给定t, 状态值独立于选择的动作, 因此对动作选择没有贡献, 所以使用公式(4)代替.
- 输入也是个体网络隐特征的组合∑ihV,i(τi)
损失函数
其中
- r是在观察τ执行动作u转移到τ′的奖励.
- Ltd学习Qjt, 通过最小化TD误差估计真实Q值;
- Lopt和Lnopt为了在把Qjt分解为[Qi]时满足条件(4).
- Lnopt用来在每一步检查样例中选择的动作是否满足(4b), Lopt检查最优局部动作是否满足(4a).
- 根据网络对样本中动作满足(4a)或(4b)的程度定义损失, 实现(4); 但是验证(4a)需要太多样本, 因为最优动作很少, 需要大量采样.
- 因为目标是学习Qjt′和Vjt分解给定的Qjt, 本文在学习Lopt和Lnopt时通过固定Qjt稳定学习.
2.2 QTRAN-alt
使用一种反事实方法, 前述定理1通过(4a)强化IGM, 通过(4b)确定个体Q值[Qi]和状态值Vjt如何跟踪Qjt, 控制构造函数地稳定性.(4b)过于稀疏导致不能构造正确的分解形式, 也就是说, (4b)对于非最优动作施加了坏的影响, 反过来影响稳定性和收敛速度. 关键在于如何在非最优动作处应强化什么条件.
定理2
| 定理1及其必要条件通过替换(4b)为(7)成立: |
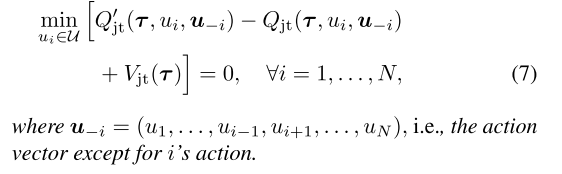 |
条件(7)在遵循定理1的同时令至少一个动作为0, 条件比(4b)更强.(4b)要求对任意τ, Qjt(t,u)−Vjt(t)≤Qjt′(t,u)≤Qjt′(t,u¯), 此时可能存在Qjt′(t,u)和Qjt′(t,u¯)相近, 但是Qjt(t,u)比Qjt(t,u¯)小很多. 带来不稳定.
条件(7)限制了上述问题, 加宽了Qjt(t,u)和Qjt(t,u¯)之间的gap.
QTRAN-alt网络只用一次前向, 就可以计算所有i的Qjt(t,⋅,u−i)和Qjt′(t,⋅,u−i).
因此, 每个智能体都有一个反事实联合网络, 给定其他智能体的动作, 其对于每个可能动作的输出为Qjt(t,⋅,u−i). 从其他智能体得到hv,i(τi)和合并隐特征∑j≠ihQ,j(τj,uj).
最后, 对于所有智能体, Qjt′(t,⋅,u−i)=Qi(τi,⋅)+∑j≠iQj(τj,uj). 通过损失函数用Lnopt−min代替Lnopt实现:
3 伪代码