4 周博磊RL-3-model_free
MC 方法
1. MC增量迭代公式

2. MC与DP区别
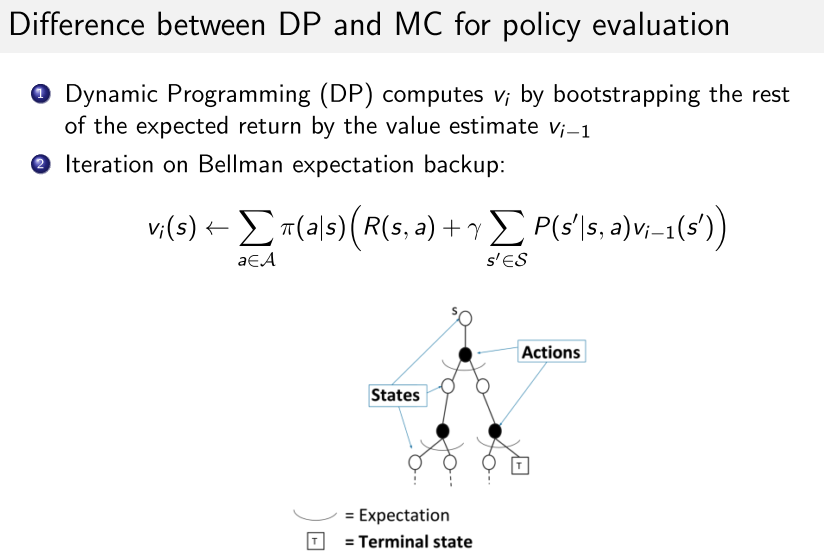
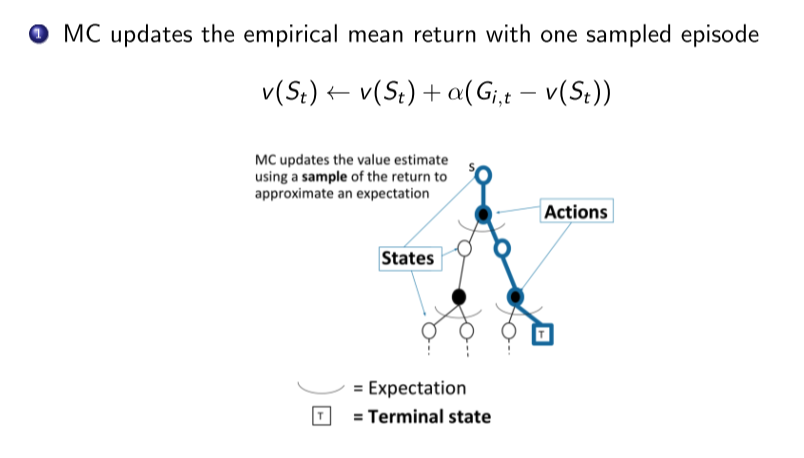
- MC可用于model-free
- 不关心与采样轨迹无关的状态,减少状态更新成本;
- 在状态空间特别巨大的环境中,状态转移函数很复杂。使用MC采样效率更高
TD

TD 与MC对比
- TD可以online学习; MC必须等一个回合结束
- TD可以使用不完整的序列学习,MC必须完整序列
- TD可以用于连续或无终止状态的环境,MC只用于episodic的环境
- TD利用马尔科夫性,在MDP环境效率更高;MC没用马尔科夫性。
- TD: 低方差,online,不完整序列
n-step TD

TD, MC, DP

model-free Control
MC



TD - 可以online
On-Policy

Off-Policy
- on-policy: 行动策略不使用最优策略,保证探索所有动作,然后减少探索性(比如epsilon-greedy)
- 不适合大状态空间的问题, 仅完成依次遍历, 就要计算存储每一个状态.
- 是从当前策略导出的, 实际执行了.
off-policy:学习的策略和行动策略不同。行动策略可以更具探索性。
- 行为策略可以更具有探索性,
- 没有实际执行.
- 样本重用, 样本效率高
- 可以使用人类或其他数据(模仿学习)
- 没有去采样下一个action
- 但是方差更大, 收敛更慢
- 一般需要使用重要性采样., 重要性采样比只与两个策略和样本数据相关, 与环境转移方程无关.


on-policy, off-policy 对比

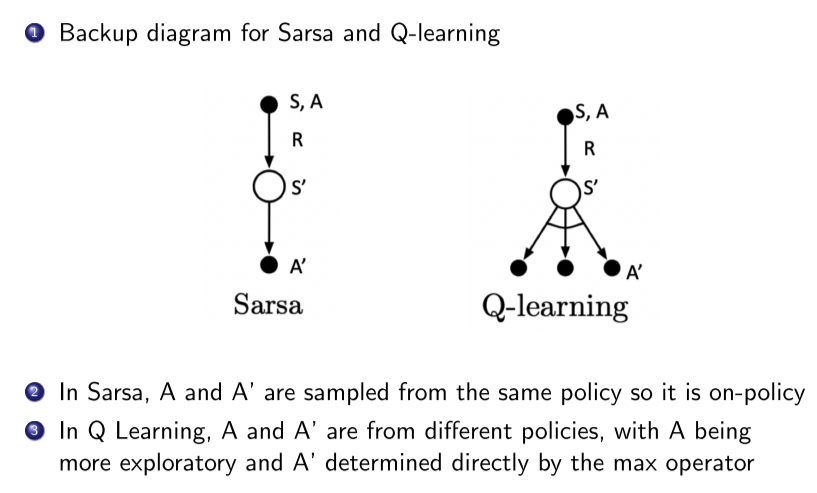
例子
https://github.com/cuhkrlcourse/RLexample/tree/master/modelfree
重要性采样


